Chiral Software’s ZombieCam system has been selected for participation in the upcoming JIFX experiments. The team is looking forward to testing the technology and discovering creative ways of interfacing with other fresh-out-of-the-lab technology. As always the goal is to use our creativity and innovation to defend the United States and keep us ahead of our adversaries. ZombieCam is not just a camera, it is a platform for sensing and interacting with the environment.
Category: Uncategorized
Chiral Software begins research in embedded machine learning for USDA Forest Service
Chiral Software was awarded a contract today to continue development of the CoyoteCam embedded system for machine learning based wildlife management. The goal is to automatically select animals using images, to control an electric fence which will selectively exclude a target species. The CoyoteCam system uses NVidia modules, with battery and solar power, for deployment at the Forest Service research station at the Department of Energy Savannah River Site.
This is an exciting use of machine learning and may have applications to many tasks for surveillance, security, and wildlife management, and continues Chiral’s earlier research work.
A Survey of Modern AI Physics Modeling
Given a scenario, can an AI model accurately predict the trajectory of moving objects? Can it use knowledge of friction and mass to anticipate the result of objects colliding? These are innate abilities we may take for granted, but attempts to replicate them reveal their complexity.
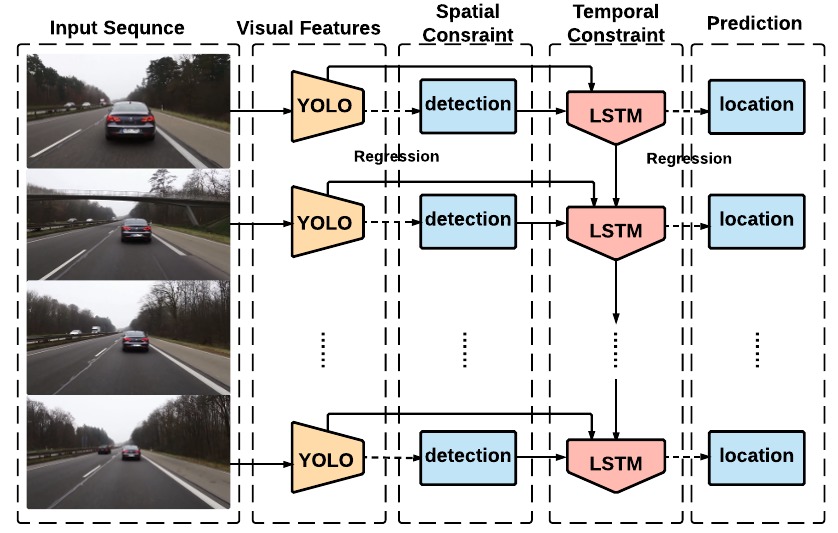
The first project we’ll review isn’t a complete physics system, but it notable for the way it integrates object momentum in a object-detection system. YOLO, short for “You only look once”, is a groundbreaking object-detection system that combines the region proposal and classification steps into one fast regression computation. This system can identify and track objects in real-time. In 2016 PhD student Guanghan Ning released an ingenious modification to YOLO called ROLO. While YOLO would lose track of car moving behind a tree, ROLO could accurately track the car even though it was temporarily obscured by a tree. “Recurrent YOLO for object tracking”, or ROLO, included a long short term memory network, or LSTM. This gave the system a memory of an object’s location and the ability to forecast it. Using the memory, the system learned the speed and momentum of an object, and could estimate it’s position when moving behind an obstacle like a wall, tree, etc.
{kind=link}
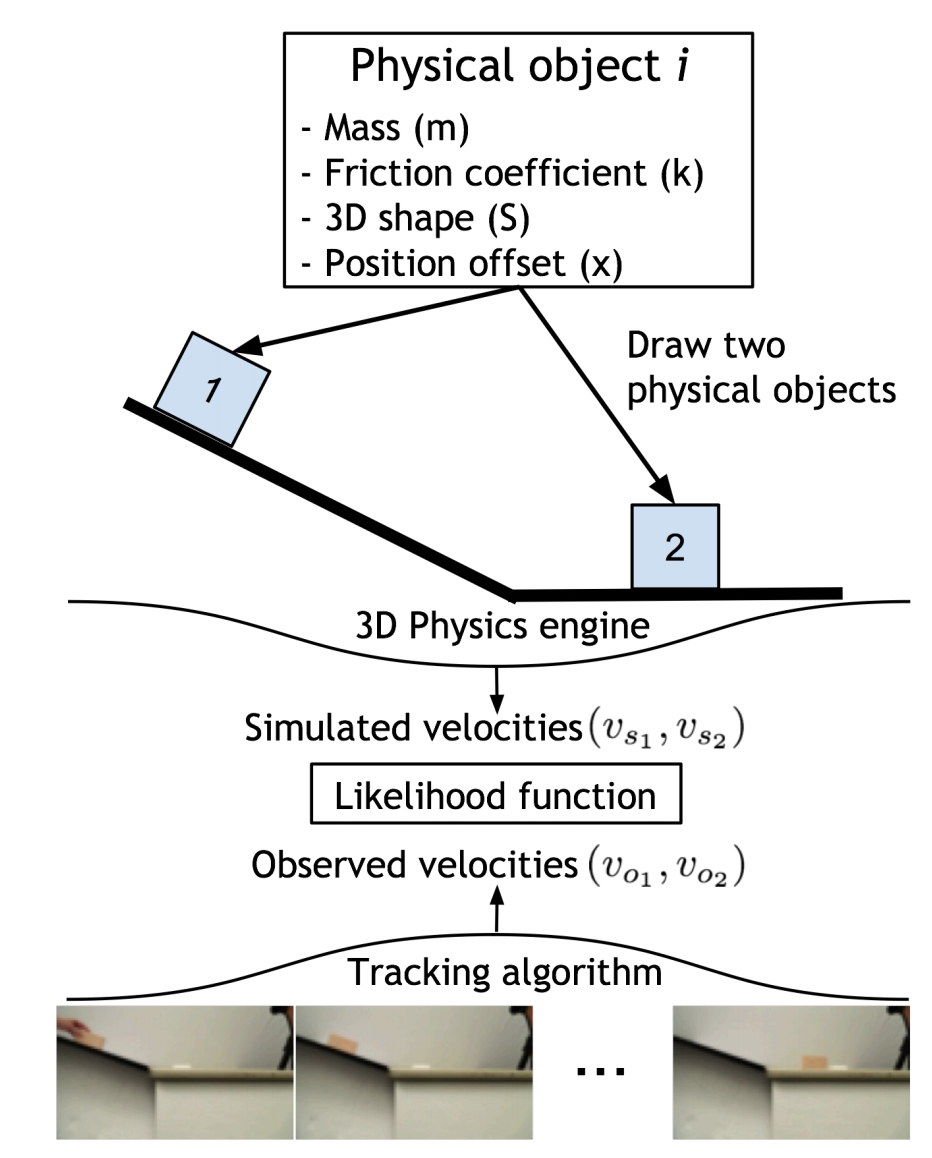
MIT published Galileo in 2015. This system combined deep learning and 3D physics modeling. The researchers set up a simple scenario: an object sliding down an incline and colliding with an object at the bottom. The deep network would estimate physical properties of the two objects. These included mass, friction coefficient, 3D shape, and position. These variables were then applied to a 3D simulation of the same scenario. The 3D physics engine would simulate the sliding and collision of these objects. A tracking algorithm would also calculate the velocity of the real object. With these estimated and recorded inputs, the system simulated and predicted the outcome of the collision. When asked “How far will the object travel after collision?”, humans were accurate 75.3% of the time, while Galileo achieved 71.9% accuracy. Though impressive, this approach requires the physics scenario to be strictly defined.
The next paper attempts to predict physics in a more versatile manner than Galileo. Given an input image and object of focus, the model can automatically infer the correct physics scenario and forecast trajectory. “Newtonian Image Understanding: Unfolding the Dynamics of Objects in Static Images” comes from the Allen Institute for Artificial Intelligence
and the University of Washington. The model consists of two branches. The first is given a video frame with a mask highlighting the object of interest. The second branch is trained on a 3D animation of 12 physics scenarios. Given the input image, the system predicts the correct movement, and then predicts the current state (is the ball already flying though the air or is it at rest?). Though impressive in its versatility, this system is limited to 12 physics scenarios and lacks a thorough internal physics model.
In “Learning Physical Intuition of Block Towers by Example” (2016), Facebook AI Research demonstrated a deep convolutional network that could predict the stability and trajectory of stacked blocks. This approach differs from the above in that it did not leverage 3D modeling for prediction. Instead, this approach relies entirely on deep learning. The models performed well compared to human subjects, and could generalize to unseen scenarios. The figure below shows the model’s results on two scenarios. The figures contain the input image (left), the true outcome (top black background), and the predicted outcome (bottom black background).

Though an array of modern AI physics systems exist, none achieve the versatility and understanding of human cognition. The approaches may utilize prior physics knowledge in the form of 3D modeling, or they may be fully-deep and infer physics knowledge during training. Both approaches have advantages and disadvantages, and both achieve impressive performance in their test scenarios.